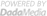 인포그래픽=AXINOVA평생교육원 AI교육연구소 AI 이미지 생성
인포그래픽=AXINOVA평생교육원 AI교육연구소 AI 이미지 생성
1. 서론: '코드 레드'와 패러다임의 전환
1.1 전략적 배경과 시장의 위기감
2025년 12월, OpenAI의 GPT-5.2 출시는 인공지능 산업의 역사에서 단순한 모델 업데이트를 넘어선 하나의 분기점으로 기록될 전망이다. 이 모델의 출시는 내부적으로 발령된 '코드 레드(Code Red)'라는 비상경영 체제 하에서 이루어졌다.1 이는 2022년 ChatGPT 출시 이후 독주 체제를 유지해오던 OpenAI가 처음으로 구글(Google)의 Gemini 3와 앤스로픽(Anthropic)의 Claude Opus 4.5라는 강력한 경쟁자들에게 기술적 우위를 위협받는 상황에 직면했음을 시사한다. 특히 구글의 Gemini 3가 멀티모달 추론과 긴 문맥 처리 능력에서 GPT-5(초기 버전)를 능가한다는 벤치마크 결과들이 잇따라 발표되면서, 샘 알트먼(Sam Altman) CEO는 내부 프로젝트의 우선순위를 전면 재조정하고, 광고 통합이나 장기적인 에이전트 실험과 같은 주변부 프로젝트를 일시 중단시킨 채 핵심 모델의 추론 능력 향상에 모든 엔지니어링 자원을 집중시키는 결단을 내렸다.3
이러한 배경에서 탄생한 GPT-5.2는 '대화형 AI(Chatbot)'의 시대를 종식하고 '추론형 에이전트(Reasoning Agent)'의 시대를 여는 전략적 무기로 포지셔닝되었다. 과거의 모델들이 인간과의 자연스러운 대화를 목표로 했다면, GPT-5.2는 스프레드시트 작성, 프레젠테이션 구성, 결함 없는 코드 생성 등 실질적인 '경제적 가치(Economic Value)'를 창출하는 결과물, 즉 아티팩트(Artifact) 생성에 초점을 맞추고 있다.5 이는 AI가 단순한 정보 검색이나 요약 도구를 넘어, 전문적인 지식 노동(Knowledge Work)을 직접 수행하는 주체로 진화했음을 의미한다.
1.2 모델의 세분화와 아키텍처의 분기
GPT-5.2 시리즈의 가장 큰 특징은 단일 거대 모델 전략을 버리고, 사용자의 의도와 작업의 복잡도에 따라 세 가지 계층으로 모델을 분화했다는 점이다. 이는 컴퓨팅 자원의 효율적 배분과 사용자 경험의 최적화를 동시에 달성하기 위한 전략적 선택으로 해석된다.
모델 명칭 | 주요 특징 및 타겟 시장 | 기술적 차별점 |
GPT-5.2 Instant | 저지연(Low-latency), 일상적인 대화, 단순 정보 검색 | 경량화된 파라미터 구조, 빠른 응답 속도, 추론 체인 최소화.1 |
GPT-5.2 Thinking | 코딩, 수학, 데이터 분석, 복잡한 논리 추론 | '생각의 사슬(Chain-of-Thought)' 기술 적용, 가변적 추론 시간, 높은 신뢰성.1 |
GPT-5.2 Pro | 고난도 과학 연구, 복잡한 법률 검토, 최상위 추론 작업 | 최대 컴퓨팅 자원 할당, 심층 탐색 트리(Deep Search Tree) 활용, 최고 비용.1 |
특히 'Thinking'과 'Pro' 모델의 도입은 AI의 추론 과정을 '시스템 2(System 2)'적 사고, 즉 느리지만 깊이 있는 사고 과정으로 구조화했다는 점에서 기술적 의의가 크다. 이는 사용자가 질문을 던지면 즉시 답변을 생성하던 기존 방식과 달리, 모델이 내부적으로 문제를 분해하고, 계획을 수립하며, 스스로 검증하는 과정을 거친 후 최종 답변을 내놓는 방식을 채택했음을 의미한다.9
2. 아키텍처 혁신과 기술적 심층 분석
2.1 추론 토큰(Reasoning Tokens)과 이중 처리 과정
GPT-5.2의 핵심적인 기술적 도약은 '추론 토큰'의 도입에 있다. 사용자가 API를 통해 모델에 접근할 때, 모델은 즉각적으로 텍스트를 생성하는 대신 내부적인 사고 과정을 수행한다. 이 과정에서 생성되는 토큰들은 사용자에게 보이지 않지만, 모델의 컨텍스트 윈도우(Context Window)를 점유하며 최종 답변의 품질을 결정짓는 핵심 요소로 작용한다.10
이 메커니즘은 강화 학습(Reinforcement Learning)을 통해 모델이 "생각하는 법"을 학습한 결과이다. 이전 모델인 o1 시리즈에서 실험적으로 도입되었던 이 기능은 GPT-5.2에서 완성형으로 구현되었으며, 특히 수학적 문제 해결이나 복잡한 코딩 작업에서 그 진가를 발휘한다. 예를 들어, 사용자가 복잡한 알고리즘 작성을 요청했을 때, GPT-5.2 Thinking 모델은 먼저 문제의 요구사항을 분석하고, 엣지 케이스(Edge Case)를 식별하며, 최적의 설계를 계획하는 일련의 '사고 토큰'을 생성한다. 이후 이 계획에 따라 실제 코드를 작성하게 되는데, 이 과정은 사용자에게는 수 초에서 수 분의 지연 시간(Latency)으로 나타나지만, 결과물의 정확도는 비약적으로 상승한다.9
이러한 구조는 기술적으로 '적응형 연산(Adaptive Computation)'의 형태를 띤다. 즉, 모든 토큰 생성에 동일한 연산 자원을 투입하는 것이 아니라, 난이도가 높은 구간에서는 더 많은 추론 토큰을 할당하여 깊이 있는 사고를 수행하고, 단순한 구간에서는 빠르게 처리하는 동적 할당이 이루어지는 것이다. 이는 기존 LLM이 가진 '할루시네이션(Hallucination)' 문제를 논리적 검증 단계를 통해 사전에 차단하는 효과를 가져온다.13
2.2 40만 토큰의 컨텍스트 윈도우와 '니들 인 어 헤이스택'
GPT-5.2는 400,000 토큰이라는 방대한 컨텍스트 윈도우를 제공한다.14 이는 영문 소설 수십 권, 혹은 수백 개의 코드 파일, 방대한 법률 문서를 한 번의 세션에 모두 입력할 수 있는 용량이다. 과거 모델들이 긴 문맥을 처리할 때 중간 부분의 정보를 망각하거나 정확도가 떨어지는 'Lost in the Middle' 현상을 겪었던 것과 달리, GPT-5.2는 이 방대한 정보 속에서 특정 정보를 정확하게 찾아내는 '건초더미 속 바늘 찾기(Needle in a Haystack)' 테스트에서 탁월한 성능을 입증했다.16
이러한 성능 향상은 모델이 전체 문맥을 한 번에 조망하고, 추론 능력을 활용하여 정보 간의 연관성을 파악하는 능력이 강화되었기 때문이다. 특히 기업 환경에서 레거시 코드베이스 전체를 분석하여 리팩토링 계획을 세우거나, 수천 페이지에 달하는 계약서들을 비교 분석하여 리스크를 찾아내는 작업에서 40만 토큰의 컨텍스트는 단순한 양적 확장이 아닌 질적 도약을 의미한다.5 또한, 128,000 토큰의 최대 출력(Max Output) 제한은 모델이 단순히 요약이나 단답형 대답을 하는 것을 넘어, 실행 가능한 전체 애플리케이션 코드나 상세한 기술 보고서를 끊김 없이 생성할 수 있게 해준다.15
2.3 라우터(Router) 시스템과 사용자 경험의 변화
OpenAI는 사용자의 쿼리를 분석하여 적절한 모델로 연결해주는 지능형 라우터 시스템을 도입했다. 사용자가 "생각해 봐(Think harder)"라고 명시하거나, 쿼리의 복잡도가 일정 수준 이상이라고 판단되면 시스템은 자동으로 'Thinking' 또는 'Pro' 모드로 전환한다.7 이는 사용자가 매번 모델을 수동으로 선택해야 하는 번거로움을 줄여주지만, 동시에 예측 불가능한 지연 시간을 초래하기도 한다.
이러한 변화는 AI 인터페이스의 패러다임을 '실시간 채팅'에서 '비동기 작업 요청'으로 변화시키고 있다. 사용자는 즉각적인 대답을 기대하기보다, AI에게 작업을 맡기고 다른 업무를 보다가 알림을 받고 결과를 확인하는 방식에 익숙해져야 할 것이다. 이는 AI가 단순한 대화 상대가 아니라, 독립적으로 업무를 수행하는 '에이전트'로 진화하고 있음을 보여주는 사용자 경험(UX)상의 증거이다.
3. 성능 벤치마크와 경쟁 우위 분석
3.1 GDPval: 경제적 유용성의 새로운 척도
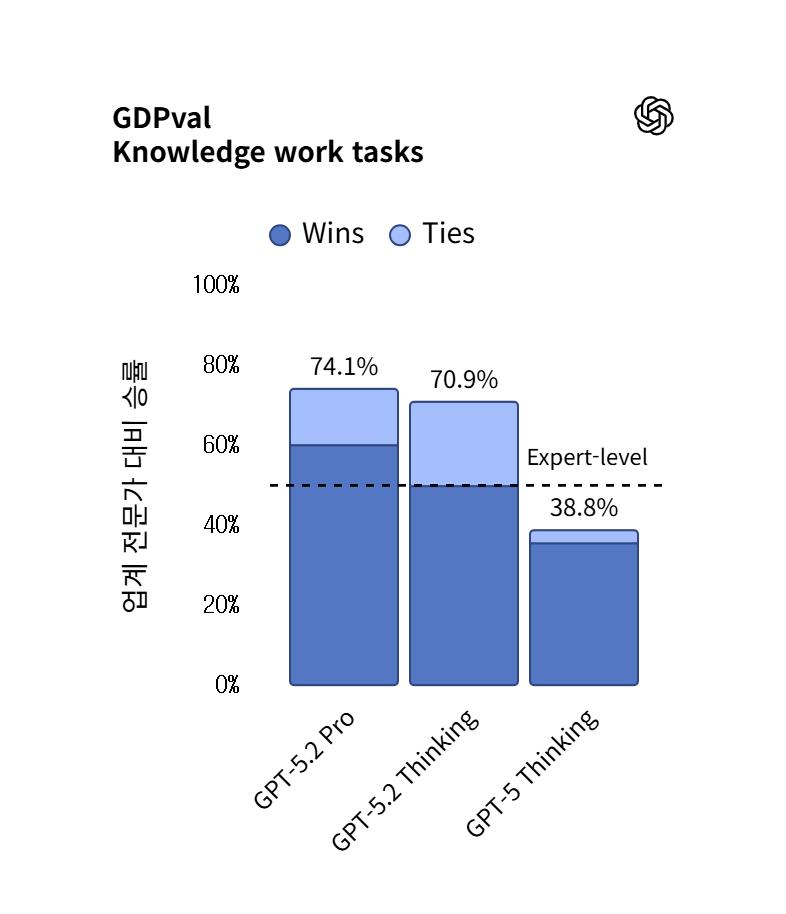
GPT-5.2의 출시와 함께 OpenAI는 GDPval이라는 새로운 벤치마크를 제안했다. 기존의 학술적 벤치마크들이 모델의 언어 능력이나 상식 추론을 측정했다면, GDPval은 미국 GDP의 5% 이상을 차지하는 9개 산업군, 44개 직업군에서 수행되는 실제 지식 노동 작업 1,320개를 평가 기준으로 삼는다.18
이 벤치마크에서 GPT-5.2 Thinking 모델은 70.9%의 승률을 기록하며, 인간 전문가들이 수행한 결과물과 대등하거나 그 이상의 성과를 보였다.7 이는 전작인 GPT-5.1 Thinking(38.8%)에 비해 두 배 가까이 향상된 수치이다. 특히 주목할 점은 OpenAI가 이 모델이 인간 전문가 대비 11배 더 빠른 속도로, 1% 미만의 비용으로 업무를 수행할 수 있다고 주장한다는 점이다.7 이는 기업 경영진에게 인건비 절감과 생산성 향상이라는 강력한 유인을 제공하며, 향후 지식 노동 시장에 큰 파장을 예고한다.
하지만 GDPval은 OpenAI의 내부 벤치마크라는 점에서 객관성에 대한 비판도 존재한다. '잘 정의된(well-specified)' 작업이라는 전제 조건은 실제 업무 현장의 모호성, 사내 정치, 비언어적 맥락 등을 배제한 실험실적 환경일 가능성이 높기 때문이다.19 그럼에도 불구하고, 엑셀 모델링, 제안서 작성, 데이터 시각화 등 정형화된 업무 영역에서 GPT-5.2가 보여주는 역량은 현존하는 모델 중 가장 실용적이라는 평가를 받는다.
3.2 수학과 과학 분야의 초월적 성능 (Superhuman Performance)
GPT-5.2는 STEM(과학, 기술, 공학, 수학) 분야에서 기존 벤치마크를 무의미하게 만들 정도의 압도적인 성능을 보여주었다.
- AIME 2025 (미국 수학 초청 경시대회): 도구(Tools)를 사용하지 않고도 100.0%의 정답률을 기록했다.7 이는 구글의 Gemini 3 Pro(95.0%)를 능가하는 수치이며, 고등학교 수준의 수학 경시대회 문제를 완벽하게 풀어낼 수 있음을 의미한다. 이는 모델의 논리적 추론 능력이 인간 최상위권 학생 수준을 넘어섰음을 시사한다.
- GPQA Diamond: 대학원 수준의 과학 난제 해결 능력을 평가하는 이 벤치마크에서 GPT-5.2 Pro는 92.4%를 기록했다.7 이는 해당 분야의 박사급 전문가들과 대등한 수준이며, 구글의 Gemini 3 Deep Think(93.8%)와 통계적 오차 범위 내에서 경쟁하는 최상위권 성적이다.19
- FrontierMath: 기존 벤치마크가 포화 상태에 이르자 새롭게 고안된 고난도 수학 연구 벤치마크인 FrontierMath에서도 40.3%를 기록하며, 아직 미지의 영역인 수학적 발견(Discovery) 단계로 나아가고 있음을 보여준다.7
3.3 코딩 및 소프트웨어 엔지니어링 역량
소프트웨어 개발 영역에서 GPT-5.2는 주니어 개발자를 대체하거나 강력하게 보조할 수 있는 수준에 도달했다.
- SWE-bench Verified: 실제 GitHub 이슈를 해결하는 능력을 평가하는 이 테스트에서 80.0%를 기록하여 GPT-5.1(76.3%)을 앞섰다.7
- SWE-bench Pro: 더 복잡하고 긴 호흡의 엔지니어링 과제를 다루는 Pro 버전에서도 55.6%를 기록하며 업계 최고 수준을 입증했다.7
개발자 커뮤니티의 초기 반응은 엇갈리는데, 새로운 프로젝트를 처음부터 구축하거나(Greenfield projects) 대규모 리팩토링을 수행하는 데에는 GPT-5.2가 탁월하다는 평가가 지배적이다. 그러나 기존의 복잡한 레거시 코드베이스 내에서 맥락을 파악하고 섬세하게 수정하는 작업에서는 앤스로픽의 Claude Opus 4.5가 여전히 선호되는 경향이 있다.21 Claude는 더 자연스러운 협업 스타일과 '컴퓨터 사용(Computer Use)' 능력에서 강점을 보이는 반면, GPT-5.2는 압도적인 추론 능력과 긴 출력 길이를 바탕으로 '한 번에 완벽한 코드'를 생성하는 데 집중한다.22
3.4 비전(Vision) 및 멀티모달 능력
GPT-5.2 Thinking은 차트 해석, 도표 분석, GUI(그래픽 사용자 인터페이스) 이해 등 시각적 정보를 논리적으로 처리하는 능력에서 비약적인 발전을 이루었다.
- CharXiv Reasoning: 과학 논문의 차트를 해석하고 추론하는 벤치마크에서 88.7%를 기록했다.7
- 실세계 적용: 저화질의 메인보드 사진에서 부품의 위치를 식별하고 바운딩 박스(Bounding Box)를 생성하는 테스트에서 이전 모델보다 훨씬 정교한 인식을 보여주었다.7 그러나 램 슬롯이나 PCIe 슬롯을 잘못 식별하는 등 여전히 하드웨어적인 전문 지식에서는 할루시네이션이 발생할 수 있음이 사용자들에 의해 지적되었다.23
- 경쟁 현황: 구글의 Gemini 3는 방대한 유튜브 데이터를 학습하여 동영상 이해 및 네이티브 멀티모달 처리에서 우위를 점하고 있는 반면1, GPT-5.2는 정적인 이미지에서 구조화된 데이터를 추출하고 이를 기반으로 논리적 결론을 도출하는 데 특화되어 있다.
4. 지능의 경제학: 가격 정책과 토크노믹스(Tokenomics)
4.1 고비용 추론의 시대
GPT-5.2의 가격 정책은 AI 시장의 양극화를 예고한다. OpenAI는 단순한 텍스트 생성이 아닌, 고도의 추론 능력에 대해 높은 프리미엄을 부과하는 전략을 취했다.
모델 | 입력 비용 (100만 토큰 당) | 캐시된 입력 (100만 토큰 당) | 출력 비용 (100만 토큰 당) |
GPT-5.2 | $1.75 | $0.175 | $14.00 |
GPT-5.2 Pro | $21.00 | - | $168.00 |
GPT-5 Mini | $0.25 | $0.025 | $2.00 |
자료: 8
특히 GPT-5.2 Pro 모델의 출력 비용인 $168.00은 충격적인 수준이다. 이는 Pro 모델이 생성하는 텍스트를 단순한 문장이 아니라, 고도로 정제된 '지적 자산'으로 간주하겠다는 의지를 보여준다. 예를 들어, Pro 모델을 사용하여 10,000 토큰 분량의 복잡한 법률 검토 보고서를 작성할 경우, 한 번의 API 호출에 약 2달러 가까이 소요된다. 이는 개인 사용자가 재미로 사용하기에는 부담스러운 가격이지만, 시간당 수백 달러를 청구하는 변호사나 컨설턴트의 업무를 대체한다고 가정하면 여전히 경제적이다. 이는 AI가 '소비재(Commodity)'에서 '자본재(Capital Goods)'로 성격이 변화하고 있음을 시사한다.
4.2 캐싱(Caching) 전략과 락인(Lock-in) 효과
높은 비용을 상쇄하기 위해 OpenAI는 캐시된 입력(Cached Input)에 대해 90% 할인($0.175)이라는 파격적인 인센티브를 제공한다.15 이는 에이전트 워크플로우에서 동일한 코드베이스나 문서를 반복적으로 참조해야 하는 상황을 고려한 것이다. 개발자들은 비용 절감을 위해 애플리케이션 구조를 OpenAI의 캐싱 메커니즘에 최적화해야 하며, 이는 결과적으로 타 플랫폼으로의 이전을 어렵게 만드는 기술적/경제적 락인 효과를 유발한다.
4.3 보이지 않는 비용: 추론 토큰 과금
기업 고객들이 가장 유의해야 할 점은 추론 토큰(Reasoning Tokens)이 출력 토큰으로 과금된다는 사실이다.10 사용자가 API를 호출할 때, 모델이 내부적으로 얼마나 많은 생각을 할지 사전에 정확히 예측하기 어렵다. 복잡한 문제의 경우 모델이 수천 토큰을 '생각'하는 데 사용할 수 있으며, 이 비용은 고스란히 청구된다. 이는 API 비용 예측을 어렵게 만들며, 개발자들은 reasoning_effort 파라미터(low, medium, high)를 통해 모델의 사고 깊이를 인위적으로 조절해야 하는 새로운 최적화 과제를 안게 되었다.8
5. 엔터프라이즈 통합과 마이크로소프트 파운드리(Foundry)
5.1 챗봇에서 엔터프라이즈 에이전트로
마이크로소프트는 GPT-5.2를 Azure AI Foundry 플랫폼의 핵심 엔진으로 즉각 통합했다. 이는 GPT-5.2가 단순한 API를 넘어 기업의 기간계 시스템과 연동되는 '두뇌' 역할을 수행함을 의미한다.5 Foundry 내에서 GPT-5.2는 다음과 같은 엔터프라이즈급 기능을 제공한다:
- 관리형 ID 및 거버넌스: 자율 에이전트가 기업의 보안 정책을 위반하지 않고 데이터에 접근하도록 제어한다.
- 감사 가능한(Auditable) 코드 생성: 에이전트가 생성한 코드는 물론, 해당 코드가 어떤 논리로 작성되었는지에 대한 설명과 테스트 케이스를 함께 생성하여 인간 개발자가 검증할 수 있도록 한다.
- 멀티 에이전트 오케스트레이션: GPT-5.2 Thinking 모델이 '컨트롤러' 역할을 맡아 전체 작업 흐름을 설계하고, 단순 반복 작업은 저렴한 GPT-5 Mini 모델이나 외부 도구에 위임하는 구조를 지원한다.
5.2 산업별 구체적 활용 사례
보고서는 GPT-5.2가 특정 산업 분야에서 인간의 업무를 대체하거나 고도화하는 사례를 제시한다.
- 금융: 트레이딩 시나리오에 대한 '윈드 터널링(Wind Tunneling)' 테스트를 수행하고, 리스크 트레이드오프를 설명하는 방어 가능한(Defensible) 보고서를 작성한다.5
- IT 현대화: 40만 토큰의 컨텍스트를 활용하여 COBOL이나 구형 Java로 작성된 레거시 시스템 전체를 분석하고, 이를 최신 언어로 변환하는 마이그레이션 계획과 코드를 동시에 생성한다.5
- 법률: 수천 건의 계약서를 동시에 검토하여 특이 조항을 식별하고, 법적 리스크를 분석하는 작업에서 높은 회상률(Recall)을 바탕으로 인간 보조원(Paralegal)의 역할을 수행한다.14
6. 안전성, 사회적 영향 및 윤리적 논쟁
6.1 '파터널리즘(Paternalism)' 논란과 과도한 안전장치
OpenAI는 GPT-5.2를 역대 가장 안전한 모델로 홍보하며, 특히 정신 건강 위기나 자해 위험 상황에서의 대응 능력을 강화했다고 밝혔다.27 시스템 카드(System Card)에 따르면, 모델은 사용자의 정서적 의존을 줄이고 전문가의 도움을 받도록 유도하는 '안전한 완료(Safe Completion)' 전략을 채택했다.27
그러나 이러한 안전장치가 강화되면서, 일반 사용자들 사이에서는 모델이 지나치게 설교적이고(Preachy), 사용자를 어린아이 취급한다는(Infantilizing) 비판이 제기되고 있다.28 Reddit 등의 커뮤니티에서는 GPT-5.2가 이전 모델인 GPT-4o가 가졌던 '따뜻함'이나 '위트'를 잃어버리고, "기업적이고 멸균된(Sterile)" 톤으로 변질되었다는 불만이 폭주했다.30 마약류의 피해 감소(Harm Reduction) 정보와 같이 민감하지만 필요한 정보조차 과도하게 차단한다는 지적은 안전성과 유용성 사이의 균형에 대한 논쟁을 재점화하고 있다.
6.2 할루시네이션과 신뢰성의 역설
'Thinking' 모델의 도입으로 논리적 오류에 의한 할루시네이션은 크게 감소했다. 모델이 스스로 "이 가정이 맞나?"라고 자문하는 과정이 포함되어 있기 때문이다.31 그러나 여전히 사실관계(Factuality) 자체를 날조하는 지식 할루시네이션은 완전히 해결되지 않았다. 특히 하드웨어 부품 식별 사례에서 보듯이, 모델은 자신이 모르는 영역에 대해서도 확신에 차서 틀린 답을 내놓는 경향이 있다.23 이는 사용자가 모델의 뛰어난 추론 능력을 맹신하게 만들 수 있어 더 큰 위험을 초래할 수 있다.
6.3 지식 노동의 대체와 노동 시장의 위기
GDPval에서의 70.9% 승률은 단순한 수치 이상의 의미를 갖는다. 이는 주니어 컨설턴트, 데이터 분석가, 초급 개발자의 업무 대부분이 자동화될 수 있음을 시사한다. GPT-5.2가 생성하는 PPT 슬라이드나 엑셀 모델은 이미 실무에서 즉시 사용할 수 있는 수준에 근접했다.7 기업 입장에서는 1%의 비용으로 11배 빠른 결과물을 얻을 수 있는 유혹을 뿌리치기 힘들 것이며, 이는 향후 1~2년 내에 화이트칼라 직군, 특히 진입 단계(Entry-level)의 일자리 감소로 이어질 가능성이 매우 높다.
7. 개발자 생태계와 API 마이그레이션 가이드
7.1 파괴적 변경(Breaking Changes)과 대응 전략
GPT-5.2로의 전환은 단순한 엔드포인트 변경 이상의 엔지니어링 노력을 요구한다.
- 비동기 UX 설계: 더 이상 즉각적인 응답(TTFT)을 기대할 수 없으므로, 애플리케이션 UI는 "에이전트가 생각 중입니다"와 같은 상태를 표시하고, 긴 대기 시간을 사용자 경험에 녹여내야 한다.9
- 프롬프트 엔지니어링의 변화: 복잡한 'Chain-of-Thought' 프롬프팅을 사용자가 직접 작성할 필요가 줄어들었다. 오히려 모델에게 명확한 목표만 제시하고, 과정은 모델이 알아서 설계하도록 두는 것이 더 나은 결과를 낳는다.26
- 도구 호출(Tool Calling)의 투명화: GPT-5.2는 도구를 사용하기 전에 서문(Preamble)을 생성하여 왜 이 도구를 사용하는지 설명한다. 이는 디버깅에는 유리하지만, API 응답 파싱 로직을 수정해야 하는 번거로움을 동반한다.26
7.2 API 접근성 및 제한
현재 GPT-5.2는 무료 사용자에게는 API 접근이 허용되지 않으며, 유료 티어(Tier)에 따라 엄격한 속도 제한(Rate Limit)이 적용된다. 티어 5 사용자는 분당 4,000만 토큰까지 사용할 수 있지만, 이는 대기업 수준의 계약이 필요하다.15 파인튜닝(Fine-tuning)은 아직 지원되지 않으며, 대신 OpenAI는 GPT-5.2의 출력을 이용해 작은 모델을 학습시키는 증류(Distillation) 방식을 권장하고 있다.25
8. 3강 구도 비교 분석: OpenAI vs Google vs Anthropic
현재 AI 최전선은 세 가지 거대 모델의 각축장이다. 각 모델은 뚜렷한 강점과 약점을 가지고 있다.
비교 항목 | OpenAI GPT-5.2 | Google Gemini 3 | Anthropic Claude Opus 4.5 |
추론(Reasoning) | 최상 (Thinking/Pro) - 수학, 과학 분야 독보적 | 강력함 (Deep Think) | 경쟁력 있음 |
코딩(Coding) | '한 번에 완성'하는 능력 탁월 | 구글 생태계 통합 우수 | 유지보수 및 협업 능력 최상 |
멀티모달(Multimodal) | 차트/문서/GUI 논리적 해석 우위 | 비디오/네이티브 멀티모달 최강 | 이미지 인식 우수 |
컨텍스트(Context) | 400k (높은 정확도/회상률) | 2M+ (압도적 용량) | 200k |
가격(Pricing) | 고가 (특히 Pro 모델) | 번들링을 통한 가격 경쟁력 | 중가 |
톤앤매너(Vibe) | 기업적, 안전 제일, 다소 건조함 | 정보 중심, 검색 결합 | 인간적, 차분함, 협력적 |
종합 분석: GPT-5.2는 순수한 '지능의 깊이'와 정형화된 산출물 생성에서 승리했다. Gemini 3는 방대한 정보 처리와 비디오 이해 능력에서 우위를 점하며, Claude Opus 4.5는 개발자 경험과 인간적인 상호작용에서 독보적인 팬덤을 유지하고 있다.4
9. 결론 및 미래 전망
GPT-5.2의 출시는 인공지능이 '신기한 장난감'에서 '비싼 전문가'로 진화했음을 알리는 신호탄이다. OpenAI는 '코드 레드'를 통해 경쟁자들의 추격을 따돌리고, 다시 한번 기술적 리더십을 증명했다. 특히 100%의 수학 정답률과 전문직을 능가하는 GDPval 점수는 AI 기술이 특이점(Singularity)을 향해 가속하고 있음을 보여주는 구체적인 지표이다.
그러나 '생각하는 비용'의 급격한 증가는 AI의 접근성을 저해하는 새로운 장벽이 될 수 있다. 또한, 안전을 이유로 창의성을 억제하는 '멸균된 AI'에 대한 반발은 오픈 소스 모델이나 경쟁사 모델로의 이탈을 부추길 수 있다.
결론적으로, 2025년의 기업과 개인은 더 이상 "어떤 AI가 가장 똑똑한가?"를 묻지 않을 것이다. 대신 "누가 이 비싼 지능을 가장 효율적으로 업무에 통합하여 경제적 가치를 창출할 것인가?"가 핵심 질문이 될 것이다. GPT-5.2는 그 질문에 대한 OpenAI의 강력하고도 비싼 대답이다.
보고서 작성: 최득진 박사 (AI 리서치 컨설턴트 | ChatGPT AI 1급 지도사 | AXINOVA 평생교육원 AI교육연구소 소장)
작성일: 2025년 12월 12일
참조: 본 보고서는 OpenAI 공식 발표 자료를 바탕으로 작성되었습니다.
[참고 자료]
- 1. OpenAI launches GPT-5.2. What is it, and how can you try it? | Mashable, https://mashable.com/article/openai-launches-new-model-gpt-5-2
- 2. OpenAI launches GPT 5.2 with advanced capabilities, to compete with Google’s Gemini 3, https://timesofindia.indiatimes.com/technology/tech-news/openai-launches-gpt-5-2-with-advanced-capabilities-to-compete-with-googles-gemini-3/articleshow/125925004.cms
- 3. OpenAI launches new ChatGPT model focused on providing ‘professional’ assistance, https://www.washingtonexaminer.com/policy/technology/3915198/openai-launches-new-chatgpt-model-focused-providing-professional-assistance/
- 4. OpenAI will release GPT‑5.2 early to try and beat Google Gemini 3, https://www.techradar.com/ai-platforms-assistants/chatgpt/openai-races-gemini-3-to-the-top-with-gpt-5-2-drop-this-week
- 5. GPT‑5.2 in Microsoft Foundry: Enterprise AI Reinvented | Microsoft ..., https://azure.microsoft.com/en-us/blog/introducing-gpt-5-2-in-microsoft-foundry-the-new-standard-for-enterprise-ai/
- 6. ChatGPT-5.2 released: Cost, how to use, performance scores and is it better than Google Gemini 3?, https://www.financialexpress.com/life/technology-chatgpt-5-2-released-cost-how-to-use-performance-scores-and-is-it-better-than-google-gemini-3-4074476/
- 7. Introducing GPT-5.2, https://openai.com/index/introducing-gpt-5-2/
- 8. gpt-5.2-pro Model | OpenAI API, https://platform.openai.com/docs/models/gpt-5.2-pro
- 9. GPT-5 vs. GPT-5 Pro vs. GPT-5 “Thinking Mode”: Features, Capabilities & Differences, https://blog.promptlayer.com/gpt-5-vs-gpt-5-pro-vs-gpt-5-thinking-mode/
- 10. Reasoning models | OpenAI API, https://platform.openai.com/docs/guides/reasoning
- 11. Query reasoning models | Databricks on AWS, https://docs.databricks.com/aws/en/machine-learning/model-serving/query-reason-models
- 12. Update to GPT-5 System Card: GPT-5.2 - OpenAI, https://cdn.openai.com/pdf/3a4153c8-c748-4b71-8e31-aecbde944f8d/oai_5_2_system-card.pdf
- 13. OpenAI Launches GPT-5.2 for ChatGPT Users a Week After Declaring 'Code Red', https://www.macrumors.com/2025/12/11/openai-gpt-5-2/
- 14. OpenAI unveils ChatGPT 5.2: Top features explained and how it compares with Google Gemini 3, https://www.indiatoday.in/technology/news/story/openai-unveils-chatgpt-52-top-features-explained-and-how-it-compares-with-google-gemini-3-2834869-2025-12-12
- 15. gpt-5.2 Model | OpenAI API, https://platform.openai.com/docs/models/gpt-5.2
- 16. Thus Spake Long-Context Large Language Model - arXiv, https://arxiv.org/html/2502.17129v1
- 17. LONGEMBED: Extending Embedding Models for Long Context Retrieval - ACL Anthology, https://aclanthology.org/2024.emnlp-main.47.pdf
- 18. Are GPT-5.2's new powers enough to surpass Gemini 3? Try it and see, https://www.zdnet.com/article/new-openai-gpt-5-2-how-to-try-it/
- 19. How GPT-5.2 stacks up against Gemini 3.0 and Claude Opus 4.5 - R&D World, https://www.rdworldonline.com/how-gpt-5-2-stacks-up-against-gemini-3-0-and-claude-opus-4-5/
- 20. OpenAI releases GPT-5.2 (Instant, Thinking, Pro). Achieves 100% on AIME 2025 and beats human experts on 21. knowledge work (74.1% win rate) with Benchmarks : r/singularity - Reddit, https://www.reddit.com/r/singularity/comments/1pk4w9z/openai_releases_gpt52_instant_thinking_pro/
- 22. Claude Sonnet 4.5 vs GPT-5-Codex: what real developers say, https://open-data-analytics.medium.com/claude-sonnet-4-5-vs-gpt-5-codex-what-real-developers-say-24fe0787d0c8
- 23. Independent evaluation of GPT5.2 on SWE-bench: 5.2 high is #3 behind Gemini, 5.2 medium behind Sonnet 4.5 : r/ChatGPTCoding - Reddit, https://www.reddit.com/r/ChatGPTCoding/comments/1pk9eo5/independent_evaluation_of_gpt52_on_swebench_52/
- 24. Introducing GPT-5.2 : r/OpenAI - Reddit, https://www.reddit.com/r/OpenAI/comments/1pk4x35/introducing_gpt52/
- 25. API Pricing - OpenAI, https://openai.com/api/pricing/
- 26. OpenAI Launches GPT-5.2 'Garlic' with 400K Context Window for Enterprise Coding, https://www.eweek.com/news/openai-launches-gpt-5-2/
- 27. Using GPT-5.2 | OpenAI API, https://platform.openai.com/docs/guides/latest-model
- 28. OpenAI says GPT-5.2 is 'safer' for mental health. What does that mean?, https://mashable.com/article/openai-gpt-5-2-safer-for-mental-health
- 29. OpenAI has by far THE WORST guardrails of every single model provider - Reddit, https://www.reddit.com/r/singularity/comments/1phnf27/openai_has_by_far_the_worst_guardrails_of_every/
- 30. 'Everything I hate about 5 and 5.1, but worse': ChatGPT users disappointed by 5.2 as OpenAI's 'Code Red' fails to meet expectations, https://www.techradar.com/ai-platforms-assistants/openai/chatgpt-5-2-branded-a-step-backwards-by-disappointed-early-users-heres-why
- 31. GPT-5 is getting panned on Reddit as Sam Altman responds | Mashable, https://mashable.com/article/gpt-5-panned-on-reddit-sam-altman-ama
- 32. GPT‑5.2 Thinking: The New Standard for Advanced Reasoning and Professional AI Workflows - GlobalGPT, https://www.glbgpt.com/hub/gpt-5-2-thinking-the-new-standard-for-advanced-reasoning-and-professional-ai-workflows/
- 33. GPT 5.2 vs Gemini 3 Pro: Full 2026 Comparison of Google and OpenAI's Latest AI Models, https://www.glbgpt.com/hub/gpt-5-2-vs-gemini-3-pro-full-2026-comparison-of-google-and-openais-latest-ai-models/
- 34. Learning About The World Through Video Generation - Berkeley EECS, https://www2.eecs.berkeley.edu/Pubs/TechRpts/2024/EECS-2024-193.pdf
 AI 혁신 물결: xAI의 세계 모델, OpenAI GPT-5 업데이트, Hugging Face 오픈소스 NLP 모델 출시
2025년 말, AI 분야에서 주요 기업들의 연이은 발표가 이어지며 기술 발전의 속도가 가속화되고 있다. xAI의 로보틱스용 물리 세계 이해 모델 개발, OpenAI의 GPT-5 시리즈 업데이트, 그리고 Hugging Face의 맞춤형 NLP 오픈소스 모델 출시가 그 중심에 있다. 이러한 발전은 로보틱스, 자연어 처리, 콘텐츠 생성 등 다양한 영역에서 실용적 적용을 촉진할 ...
AI 혁신 물결: xAI의 세계 모델, OpenAI GPT-5 업데이트, Hugging Face 오픈소스 NLP 모델 출시
2025년 말, AI 분야에서 주요 기업들의 연이은 발표가 이어지며 기술 발전의 속도가 가속화되고 있다. xAI의 로보틱스용 물리 세계 이해 모델 개발, OpenAI의 GPT-5 시리즈 업데이트, 그리고 Hugging Face의 맞춤형 NLP 오픈소스 모델 출시가 그 중심에 있다. 이러한 발전은 로보틱스, 자연어 처리, 콘텐츠 생성 등 다양한 영역에서 실용적 적용을 촉진할 ...
 서울국제조각페스타 2026, 코엑스서 예술과 기업의 만남 성황
서울국제조각페스타 2026, 코엑스서 예술과 기업의 만남 성황
 [손현식 칼럼] 270만 외국인 시대, ‘함께 사는 법’은 배운 적이 없다
[손현식 칼럼] 270만 외국인 시대, ‘함께 사는 법’은 배운 적이 없다
 할리우드 배우노조, 스튜디오 측에 새 반대 제안 테이블에 올리다
할리우드 배우노조, 스튜디오 측에 새 반대 제안 테이블에 올리다
 '내란전담재판부' 의무 설치=사법 독립의 종언이자 입법 독재
'내란전담재판부' 의무 설치=사법 독립의 종언이자 입법 독재
 하나님의 축복 속에서 시작된 사랑… 특별한 결혼의 여정
하나님의 축복 속에서 시작된 사랑… 특별한 결혼의 여정

 목록
목록